RAG正在进化配资炒股评测网,但真正的突破不在参数,而在时间维度。如何让AI代理理解“知识的时间性”?如何在系统中嵌入“时态感知”的机制?本文以产品视角切入,提出“动作-时间-知识”三元协同模型,为AI产品经理提供下一代知识系统的设计思路。

用于回答问题的 RAG 或代理架构依赖于随着时间的推移不断更新的动态知识库,例如财务报告或文档,以便推理和规划步骤保持逻辑和准确。
为了处理这样的知识库,其中规模不断增长,幻觉的机会可能会增加,需要一个单独的逻辑时间(时间感知)代理管道来管理 AI 产品中这个不断发展的知识库 。
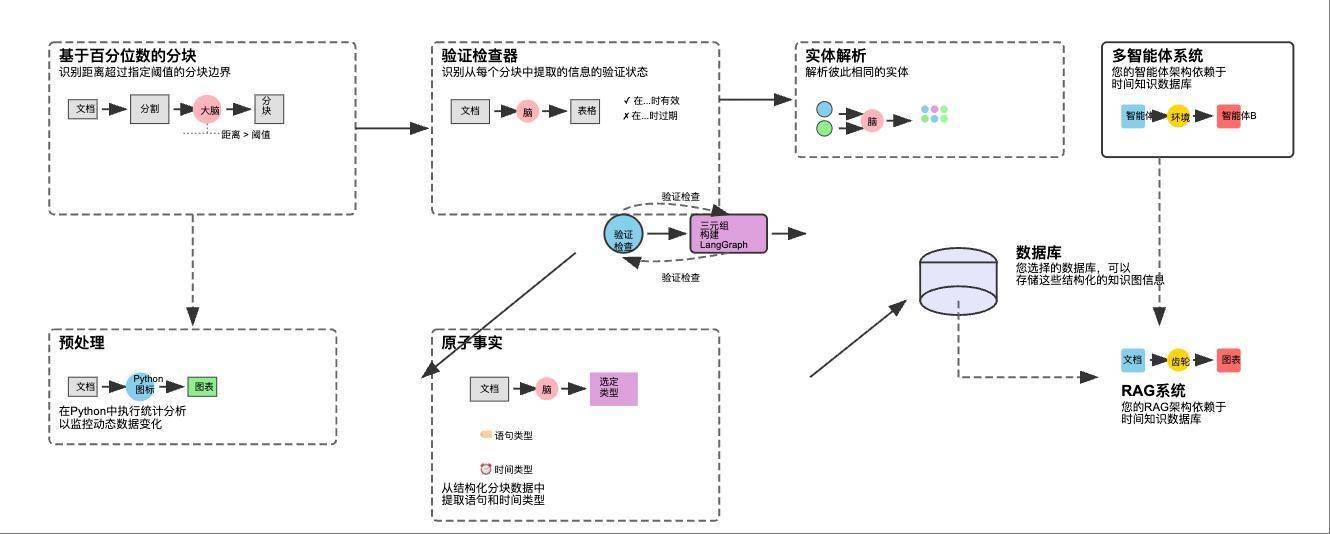 百分位语义分块:将大型原始文档分解为具有上下文意义的小文本块;原子事实:使用LLM读取每个块并提取原子事实、它们的时间戳和所涉及的实体;实体解析:通过自动查找和合并重复实体(例如,“AMD”和“AdvancedMicroDevices”)来清理数据;时间无效:当新信息到达时,通过将过时的事实标记为“过期”来智能识别和解决矛盾;知识图谱构建:将最终的、干净的、带有时间戳的事实组装成一个连接的图形结构,我们的AI代理可以查询;优化的知识库:将最终的动态知识图谱存储在可扩展的云数据库中,创建可靠、最新的“大脑”,在此基础上构建最终的RAG或代理系统;预处理和分析我们的动态数据
百分位语义分块:将大型原始文档分解为具有上下文意义的小文本块;原子事实:使用LLM读取每个块并提取原子事实、它们的时间戳和所涉及的实体;实体解析:通过自动查找和合并重复实体(例如,“AMD”和“AdvancedMicroDevices”)来清理数据;时间无效:当新信息到达时,通过将过时的事实标记为“过期”来智能识别和解决矛盾;知识图谱构建:将最终的、干净的、带有时间戳的事实组装成一个连接的图形结构,我们的AI代理可以查询;优化的知识库:将最终的动态知识图谱存储在可扩展的云数据库中,创建可靠、最新的“大脑”,在此基础上构建最终的RAG或代理系统;预处理和分析我们的动态数据公司定期分享其财务业绩的最新信息,例如股价走势、执行领导层变动等重大发展,以及前瞻性预期,例如季度收入是否预计同比增长 12% 等。
在医疗领域,ICD 编码是数据不断发展的另一个例子,从 ICD-9 到 ICD-10 的过渡使诊断代码从约 14,000 个增加到 68,000 个。
让我们加载这个数据集并对其进行一些统计分析以适应它。
# Import loader for Hugging Face datasets
from langchain_community.document_loaders import HuggingFaceDatasetLoader
# Dataset configuration
hf_dataset_name = “jlh-ibm/earnings_call” # HF dataset name
subset_name = “transcripts” # Dataset subset to load
# Create the loader (defaults to ‘train’ split)
loader = HuggingFaceDatasetLoader(
path=hf_dataset_name,
name=subset_name,
page_content_column=”transcript” # Column containing the main text
)
# This is the key step. The loader processes the dataset and returns a list of LangChain Document objects.
documents = loader.load
我们专注于该数据集的成绩单子集,其中包含有关不同公司的原始文本信息。这是数据集的基本结构,可作为任何 RAG 或 AI 代理架构的起点。
# Let’s inspect the result to see the difference
print(f”Loaded {len(documents)} documents.”)
#
#
## OUTPUT ####
Loaded 188 documents.
我们的数据中共有 188 份成绩单。这些成绩单属于不同的公司,我们需要计算我们的数据集中代表了多少个独特的公司。
# Count how many documents each company has
company_counts = {}
# Loop over all loaded documents
for doc in documents:
company = doc.metadata.get(“company”) # Extract company from metadata
if company:
company_counts[company] = company_counts.get(company, 0) + 1
# Display the counts
print(“Total company counts:”)
for company, count in company_counts.items:
print(f”
– {company}: {count}”)
#
#
## OUTPUT ####
Total company counts:
– AMD: 19
– AAPL: 19
– INTC: 19
– MU: 17
– GOOGL: 19
– ASML: 19
– CSCO: 19
– NVDA: 19
– AMZN: 19
– MSFT: 19
几乎所有公司的分配比例都相等。查看随机成绩单的元数据。
# Print metadata for two sample documents (index 0 and 33)
print(“Metadata for document[0]:”)
print(documents[0].metadata)
print(“Metadata for document[33]:”)
print(documents[33].metadata)
#
#
## OUTPUT ####
{‘company’: ‘AMD’, ‘date’: datetime.date(2016, 7, 21)}
{‘company’: ‘AMZN’, ‘date’: datetime.date(2019, 10, 24)}
公司字段仅指示成绩单属于哪家公司, 日期字段表示信息所基于的时间范围。
# Print the first 200 characters of the first document’s content
first_doc = documents[0]
print(first_doc.page_content[:200])
#
#
## OUTPUT ####
Thomson Reuters StreetEvents Event Transcript
E D I T E D V E R S I O N
Q2 2016 Advanced Micro Devices Inc Earnings Call
JULY 21, 2016 / 9:00PM GMT
=====================================
通过打印文档的样本,我们可以获得高级概述。例如,当前示例显示了 AMD 的季度报告。
成绩单可能很长,因为它们代表给定时间范围内的信息并包含大量详细信息。我们需要检查这 188 份成绩单平均包含多少个单词。
# Calculate the average number of words per document
total_words = sum(len(doc.page_content.split) for doc in documents)
average_words = total_words / len(documents) if documents else 0
print(f”Average number of words in documents: {average_words:.2f}”)
#
#
## OUTPUT ####
Average number of words in documents: 8797.124
每个成绩单 ~9K 字是相当大的,因为它肯定包含大量信息。但这正是我们所需要的,创建一个结构良好的知识库 AI 代理涉及处理大量信息,而不仅仅是几个小文档。
通常,财务数据基于不同的时间范围,每个时间范围代表有关该时期发生情况的不同信息。我们可以使用纯 Python 代码而不是 LLM 从成绩单中提取这些时间范围,以节省成本。
import re
from datetime import datetime
# Helper function to extract a quarter string (e.g., “Q1 2023”) from text
def find_quarter(text: str) -> str | None:
“””Return the first quarter-year match found in the text, or None if absent.”””
# Match pattern: ‘Q’ followed by 1 digit, a space, and a 4-digit year
match = re.findall(r”Qdsd{4}”, text)
return match[0] if match else None
# Test on the first document
quarter = find_quarter(documents[0].page_content)
print(f”Extracted Quarter for the first document: {quarter}”)
#
#
## OUTPUT ####
Extracted Quarter for the first document: Q2 2016
执行季度日期提取的更好方法是通过法学硕士,因为他们可以更深入地理解数据。但是,由于我们的数据在文本方面已经结构良好,因此我们暂时可以在没有它们的情况下继续进行。
百分位语义分块通常,我们根据随机拆分或有意义的句子边界(例如以句号结尾)对数据进行分块。但是,这种方法可能会导致丢失一些信息。
如果我们在句号处拆分,我们就失去了净收入增长是由于运营费用下降的紧凑联系。
我们将在这里使用基于百分位数的分块。让我们先了解这种方法,然后再实施它。
该文档使用正则表达式拆分为句子,通常在.、?或!之后中断。每个句子都使用嵌入模型转换为高维向量。计算连续句子向量之间的语义距离,值越大表示主题变化越大。收集所有距离,并确定所选的百分位数(例如95个百分位数)以捕获异常大的跳跃。距离大于或等于此阈值的边界标记为块断点。这些边界之间的句子被分组为块,应用min_chunk_size以避免过小的块,并在需要时buffer_size添加重叠。from langchain_nebius import NebiusEmbeddings
# Set Nebius API key (⚠️ Avoid hardcoding secrets in production code)
os.environ[“NEBIUS_API_KEY”] = “YOUR_API_KEY_HERE”
#
1. Initialize Nebius embedding model
embeddings = NebiusEmbeddings(model=”Qwen/Qwen3-Embedding-8B”)
我们正在使用 Qwen3–8B 通过 LangChain 中的 Nebius AI 生成嵌入。当然,LangChain 模块下还支持许多其他嵌入提供者。
from langchain_experimental.text_splitter import SemanticChunker
# Create a semantic chunker using percentile thresholding
langchain_semantic_chunker = SemanticChunker(
embeddings,
breakpoint_threshold_type=”percentile”, # Use percentile-based splitting
breakpoint_threshold_amount=95 # split at 95th percentile
)
我们选择了第 95 个百分位值,这意味着如果连续句子之间的距离超过该值,则将其视为断点。使用循环,我们可以简单地在成绩单上启动分块过程。
# Store the new, smaller chunk documents
chunked_documents_lc =
# Printing total number of docs (188) We already know that
print(f”Processing {len(documents)} documents using LangChain’s SemanticChunker…”)
# Chunk each transcript document
for doc in tqdm(documents, desc=”Chunking Transcripts with LangChain”):
# Extract quarter info and copy existing metadata
quarter = find_quarter(doc.page_content)
parent_metadata = doc.metadata.copy
parent_metadata[“quarter”] = quarter
# Perform semantic chunking (returns Document objects with metadata attached)
chunks = langchain_semantic_chunker.create_documents(
[doc.page_content],
metadatas=[parent_metadata]
)
# Collect all chunks
chunked_documents_lc.extend(chunks)
#
#
## OUTPUT ####
Processing 188 documents using LangChains SemanticChunker…
Chunking Transcripts with LangChain: 100%配资炒股评测网
盛多网提示:文章来自网络,不代表本站观点。
相关文章



热点资讯